In this blog post I will describe how to setup a simple CD pipeline using Knative pipeline. The pipeline takes a helm chart from a git repository and performs the following steps:
- it builds three docker images using Kaniko
- it pushes the built images to a private container registry
- it deploys the chart against a kubernetes cluster
I used IBM Cloud, both the container service IKS as well as the IBM Container Registry, to host Knative as well as the deployed Health app. I used the same IKS kubernetes cluster to run the Knative service as well as the deployed application. They are separated using dedicated namespaces, service accounts and roles. For details about setting up Knative on IBM Cloud checkout my previous blog post. The whole code is available on GitHub.
Knative Pipelines
Pipelines are the newest addition to the Knative project, which already included three components: serving, eventing and build. Quoting from the official README, “The Pipeline CRD provides k8s-style resources for declaring CI/CD-style pipelines”. The pipeline CRD is meant as a replacement for the build CRD. The build-pipeline project introduces a few new custom resource definitions (CRDs) to extend the Kubernetes API:
taskstasksrunpipelinepipelinerunpipelineresource
A pipeline is made of tasks; tasks can have input and output pipelineresources. The output of a task can be the input of another one. A taskrun is used run a single task. It binds the task inputs and outputs to specific pipelineresources. Similarly, a pipelinerun is used to run a pipeline. It binds the pipeline inputs and outputs to specific pipelineresources. For more details on Knative pipeline CRDs, see the official project documentation.
The “Health” application
The application deployed by the helm chart is OpenStack Health, or simply “Health”, a dashboard to visualize CI test results. The chart deploys three components:
- An SQL backend that uses the
postgres:alpinedocker image, plus a custom database image that runs database migrations through an init container - A python based API server, which exposes the data in the SQL database via HTTP based API
- A javascript frontend, which interacts on client side with the HTTP API
The Continuous Delivery Pipeline
The pipeline for “Health” uses two different tasks and several type of pipelineresources: git, image and cluster. In the diagram below circles are resources, boxes are tasks:
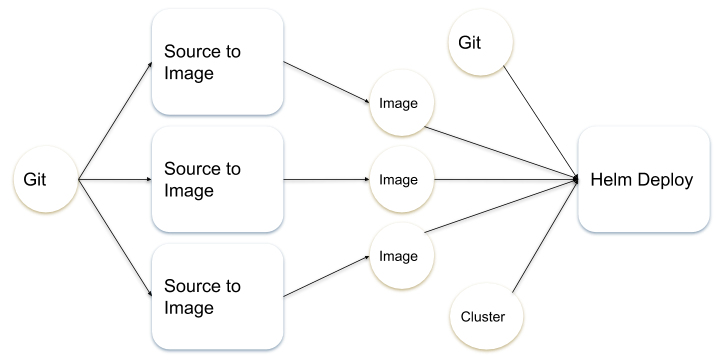
At the moment of writing the execution of tasks is strictly sequential; the order of execution is that specified in the pipeline. The plan is to use inputs and outputs to define task dependencies and thus a graph of execution, which would allow for independent tasks to run in parallel.
Source to Image (Task)
The docker files and the helm chart for “Health” are hosted in the same git repository. The git resource is thus input to the both the source-to-image task, for the docker images, as well as the helm-deploy one, for the helm char.
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: PipelineResource metadata: name: health-helm-git-knative spec: type: git params: - name: revision value: knative - name: url value: https://github.com/afrittoli/health-helm |
When a resource of type git is used as an input to a task, the knative controller clones the git repository and prepares it at the specified revision, ready for the task to use it. The source-to-image task uses Kaniko to build the specified Dockerfile and to pushes the resulting container image to the container registry.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: Task metadata: name: source-to-image spec: inputs: resources: - name: workspace type: git params: - name: pathToDockerFile description: The path to the dockerfile to build (relative to the context) default: Dockerfile - name: pathToContext description: The path to the build context, used by Kaniko - within the workspace (https://github.com/GoogleContainerTools/kaniko#kaniko-build-contexts). The git clone directory is set by the GIT init container which setup the git input resource - see https://github.com/knative/build-pipeline/blob/master/pkg/reconciler/v1alpha1/taskrun/resources/pod.go#L107 default: . outputs: resources: - name: builtImage type: image steps: - name: build-and-push image: gcr.io/kaniko-project/executor command: - /kaniko/executor args: - --dockerfile=${inputs.params.pathToDockerFile} - --destination=${outputs.resources.builtImage.url} - --context=/workspace/workspace/${inputs.params.pathToContext} |
The destination URL of the image is defined in the image output resource, and then pulled into the args passed to the Kaniko container. At the moment of writing the image output resource is only used to hold the target URL. In future Knative will enforce that every task that defines image as an output actually produces the container images and pushes it to the expected location, it will also enrich the resource metadata with the digest of the pushed image, for consuming tasks to use. The health chart includes three docker images; identically three image pipeline resources are required. They are very similar to each other in their definition, only the target URL changes. One of the three:
|
1 2 3 4 5 6 7 8 9 10 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: PipelineResource metadata: name: health-api-image spec: type: image params: - name: url description: The target URL value: registry.ng.bluemix.net/andreaf/health-api |
Helm Deploy (Task)
The three source-to-image tasks build and push three images to the container registry. They don’t report the digest of the image, however, they associate the latest tag to that digest, which allows the helm-deploy task to pull the right images, assuming only one CD pipeline runs at the time. The helm-deploy has five inputs: one git resource to get the helm chart, three image resources that correspond to three docker files and finally a cluster resource, that gives the task access to a kubernetes cluster where to deploy the helm chart to:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: PipelineResource metadata name: cluster-name spec: type: cluster params: - name: url value: https://host_and_port_of_cluster_master - name: username value: health-admin secrets: - fieldName: token secretKey: tokenKey secretName: cluster-name-secrets - fieldName: cadata secretKey: cadataKey secretName: cluster-name-secrets |
The resource name highlighted on line 4 must match the cluster name. The username is that of a service account that has enough rights to deploy helm to the cluster. For isolation, I defined a namespace in the target cluster called health. Both helm itself, as well as the health chart, are deployed in that namespace only. Helm runs with a service account health-admin that can only access the health namespace. The manifests required to set up the namespace, the service accounts, the roles and role bindings are available on GitHub. The health-admin service account token and the cluser CA certificate should not be stored in git. They are defined in a secret, which can be setup using the following template:
|
1 2 3 4 5 6 7 8 |
apiVersion: v1 kind: Secret metadata: name: __CLUSTER_NAME__-secrets type: Opaque data: cadataKey: __CA_DATA_KEY__ tokenKey: __TOKEN_KEY__ |
The template can be filled in with a simple bash script. The script works after a successful login was performed via ibmcloud login and ibmcloud target.
|
1 2 3 4 5 6 7 8 9 10 11 |
CLUSTER_NAME=${TARGET_CLUSTER_NAME:-af-pipelines} eval $(ibmcloud cs cluster-config $CLUSTER_NAME --export) # This works as long as config returns one cluster and one user SERVICE_ACCOUNT_SECRET_NAME=$(kubectl get serviceaccount/health-admin -n health -o jsonpath='{.secrets[0].name}') CA_DATA=$(kubectl get secret/$SERVICE_ACCOUNT_SECRET_NAME -n health -o jsonpath='{.data.ca\.crt}') TOKEN=$(kubectl get secret/$SERVICE_ACCOUNT_SECRET_NAME -n health -o jsonpath='{.data.token}') sed -e 's/__CLUSTER_NAME__'/"$CLUSTER_NAME"'/g' \ -e 's/__CA_DATA_KEY__/'"$CA_DATA"'/g' \ -e 's/__TOKEN_KEY__/'"$TOKEN"'/g' cluster-secrets.yaml.template > ${CLUSTER_NAME}-secrets.yaml |
Once a cluster resource is used as input to a task, it generates a kubeconfig file that can be used in the task to perform actions against the cluster. The helm-deploy task takes the image URLs from the image input resources and passes them to the helm command as set values; it also overrides the image tags to latest. The image pull policy is set to always since the tag doesn’t change, but the image does. The upgrade --install command is required so that both the first as well as following deploys may work.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: Task metadata: name: helm-deploy spec: serviceAccount: health-helm inputs: resources: - name: chart type: git - name: api-image type: image - name: frontend-image type: image - name: database-image type: image - name: target-cluster type: cluster params: - name: pathToHelmCharts description: Path to the helm charts within the repo default: . - name: clusterIngressHost description: Fully qualified hostname of the cluster ingress - name: targetNamespace description: Namespace in the target cluster we want to deploy to default: "default" steps: - name: helm-deploy image: alpine/helm args: - upgrade - --debug - --install - --namespace=${inputs.params.targetNamespace} - health # Helm release name - /workspace/chart/${inputs.params.pathToHelmCharts} # Latest version instead of ${inputs.resources.api-image.version} until #216 - --set - overrideApiImage=${inputs.resources.api-image.url}:latest - --set - overrideFrontendImage=${inputs.resources.frontend-image.url}:latest - --set - overrideDatabaseImage=${inputs.resources.database-image.url}:latest - --set - ingress.enabled=true - --set - ingress.host=${inputs.params.clusterIngressHost} - --set - image.pullPolicy=Always env: - name: "KUBECONFIG" value: "/workspace/${inputs.resources.target-cluster.name}/kubeconfig" - name: "TILLER_NAMESPACE" value: "${inputs.params.targetNamespace}" |
The location of the generated kubeconfig file is passed to the alpine/helm container via the KUBECONFIG environment variable passed on the task container. The path where the file is generated is /workspace/[name of cluster resource/kubeconfig], so it ultimately depends on the name of the target cluster.
The Pipeline
The pipeline defines the sequence of tasks that will be executed, with their inputs and outputs. The from syntax can be used to express dependencies between tasks, i.e. input of a tasks is taken from the output of another one.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: Pipeline metadata: name: health-helm-cd-pipeline spec: params: - name: clusterIngressHost description: FQDN of the ingress in the target cluster - name: targetNamespace description: Namespace in the target cluster we want to deploy to default: default resources: - name: src type: git - name: api-image type: image - name: frontend-image type: image - name: database-image type: image - name: health-cluster type: cluster tasks: - name: source-to-image-health-api taskRef: name: source-to-image params: - name: pathToContext value: images/api resources: inputs: - name: workspace resource: src outputs: - name: builtImage resource: api-image - name: source-to-image-health-frontend taskRef: name: source-to-image params: - name: pathToContext value: images/frontend resources: inputs: - name: workspace resource: src outputs: - name: builtImage resource: frontend-image - name: source-to-image-health-database taskRef: name: source-to-image params: - name: pathToContext value: images/database resources: inputs: - name: workspace resource: src outputs: - name: builtImage resource: database-image - name: helm-init-target-cluster taskRef: name: helm-init params: - name: targetNamespace value: "${params.targetNamespace}" resources: inputs: - name: target-cluster resource: health-cluster - name: helm-deploy-target-cluster taskRef: name: helm-deploy params: - name: pathToHelmCharts value: . - name: clusterIngressHost value: "${params.clusterIngressHost}" - name: targetNamespace value: "${params.targetNamespace}" resources: inputs: - name: chart resource: src - name: api-image resource: api-image from: - source-to-image-health-api - name: frontend-image resource: frontend-image from: - source-to-image-health-frontend - name: database-image resource: database-image from: - source-to-image-health-database - name: target-cluster resource: health-cluster |
Tasks can accept parameters, which are specified as part of the pipeline definition. One example in the pipeline above is the ingress domain of the target kubernetes cluster, which is used by the helm chart to set up of ingress of the deployed application. Pipelines can also accept paramters, which are specified as part of the pipelinerun definition. Parameters make it possible to keep environment and run specific values confined to pipelinerun and pipelineresource. You may notice that the pipeline includes an extra task helm-init which is invoked before helm-deploy. As the name suggests, the task initializes helm in the target cluster/namespace. Tasks can have multiple steps, so that could be implemented as a first step within the helm-deploy task. However, I wanted to keep it separated so that helm-init runs using a service account with an admin role in the target namespace, while helm-deploy runs with an unprivileged account.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: Task metadata: name: helm-init spec: serviceAccount: health-admin inputs: resources: - name: target-cluster type: cluster params: - name: targetNamespace description: Namespace in the target cluster we want to deploy to default: "default" steps: - name: helm-init image: alpine/helm args: - init - --service-account=health-admin - --wait env: - name: "KUBECONFIG" value: "/workspace/${inputs.resources.target-cluster.name}/kubeconfig" - name: "TILLER_NAMESPACE" value: "${inputs.params.targetNamespace}" |
Running the Pipeline
To run a pipeline, a pipelinerun is needed. The pipelinerun binds the tasks inputs and outputs to specific pipelineresources and defines the trigger for the run. At the momement of writing only manual trigger is supported. Since there is no native mechanism available to create a pipelinerun from a template, running a pipeline again requires changing the pipelinerun YAML manifest and applying it to the cluster again. When executed, the pipelinerun controller automatically creates a taskrun when a task is executed. Any kubernetes resources created during the run, such as taskruns, pods and pvcs, stays once the pipelinerun execution is complete; they are cleaned up only when the pipelinerun is deleted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
apiVersion: pipeline.knative.dev/v1alpha1 kind: PipelineRun metadata: generateName: health-helm-cd-pr- spec: pipelineRef: name: health-helm-cd-pipeline params: - name: clusterIngressHost value: mycluster.myzone.containers.appdomain.cloud - name: targetNamespace value: health trigger: type: manual serviceAccount: 'default' resources: - name: src resourceRef: name: health-helm-git-mygitreference - name: api-image resourceRef: name: health-api-image - name: frontend-image resourceRef: name: health-frontend-image - name: database-image resourceRef: name: health-database-image - name: health-cluster resourceRef: name: mycluster |
To execute the pipeline, all static resources must be created first, and then the pipeline can be executed. Using the code from the GitHub repo:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Create all static resources kubectl apply -f pipeline/static # Define and apply all pipelineresources as described in the blog post # You will need one git, three images, one cluster. # Generate and apply the cluster secret echo $(cd pipeline/secrets; ./prepare-secrets.sh) kubectl apply -f pipeline/secrets/cluster-secrets.yaml # Create a pipelinerun based on the demo above and create it kubectl create -f pipeline/run/run-pipeline-health-helm-cd.yaml |
A successful execution of the pipeline will create the following resources in the health namespace:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
kubectl get all -n health NAME READY STATUS RESTARTS AGE pod/health-api-587ff4fcfb-8hmpd 1/1 Running 64 11d pod/health-frontend-7c77fbc499-r4r6p 1/1 Running 0 11d pod/health-postgres-5877b6b564-fwzfk 1/1 Running 1 11d pod/tiller-deploy-5b7c84dbd6-4vcgr 1/1 Running 0 11d NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/health-api LoadBalancer 172.21.196.186 169.45.67.202 80:32693/TCP 11d service/health-frontend LoadBalancer 172.21.19.234 169.45.67.204 80:30812/TCP 11d service/health-postgres LoadBalancer 172.21.3.160 169.45.67.203 5432:32158/TCP 11d service/tiller-deploy ClusterIP 172.21.188.81 44134/TCP 11d NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/health-api 1 1 1 1 11d deployment.apps/health-frontend 1 1 1 1 11d deployment.apps/health-postgres 1 1 1 1 11d deployment.apps/tiller-deploy 1 1 1 1 11d NAME DESIRED CURRENT READY AGE replicaset.apps/health-api-587ff4fcfb 1 1 1 11d replicaset.apps/health-frontend-7c77fbc499 1 1 1 11d replicaset.apps/health-postgres-58759444b6 0 0 0 11d replicaset.apps/health-postgres-5877b6b564 1 1 1 11d replicaset.apps/tiller-deploy-5b7c84dbd6 1 1 1 11d |
All Knative pipeline resources are visible in the default namepace:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
$ kubectl get all NAME READY STATUS RESTARTS AGE pod/health-helm-cd-pipeline-run-2-helm-deploy-target-cluster-pod-649959 0/1 Completed 0 4m pod/health-helm-cd-pipeline-run-2-helm-init-target-cluster-pod-4da57e 0/1 Completed 0 7m pod/health-helm-cd-pipeline-run-2-source-to-image-health-api-pod-4f0362 0/1 Completed 0 32m pod/health-helm-cd-pipeline-run-2-source-to-image-health-database-pod-60b15f 0/1 Completed 0 14m pod/health-helm-cd-pipeline-run-2-source-to-image-health-frontend-pod-c23e71 0/1 Completed 0 24m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 172.21.0.1 443/TCP 12d NAME CREATED AT task.pipeline.knative.dev/helm-deploy 12d task.pipeline.knative.dev/helm-init 11d task.pipeline.knative.dev/source-to-image 12d NAME CREATED AT taskrun.pipeline.knative.dev/health-helm-cd-pipeline-run-2-helm-deploy-target-cluster 4m taskrun.pipeline.knative.dev/health-helm-cd-pipeline-run-2-helm-init-target-cluster 7m taskrun.pipeline.knative.dev/health-helm-cd-pipeline-run-2-source-to-image-health-api 32m taskrun.pipeline.knative.dev/health-helm-cd-pipeline-run-2-source-to-image-health-database 14m taskrun.pipeline.knative.dev/health-helm-cd-pipeline-run-2-source-to-image-health-frontend 24m NAME CREATED AT pipeline.pipeline.knative.dev/health-helm-cd-pipeline 10d NAME CREATED AT pipelinerun.pipeline.knative.dev/health-helm-cd-pipeline-run-2 32m NAME CREATED AT pipelineresource.pipeline.knative.dev/af-pipelines 12d pipelineresource.pipeline.knative.dev/health-api-image 12d pipelineresource.pipeline.knative.dev/health-database-image 12d pipelineresource.pipeline.knative.dev/health-frontend-image 12d pipelineresource.pipeline.knative.dev/health-helm-git-knative 12d |
To check if the “Health” application is running, you can hit the API using curl:
|
1 2 |
HEALTH_URL=http://$(kubectl get ingress/health -n health -o jsonpath='{..rules[0].host}') curl ${HEALTH_URL}/health-api/status |
You can point your browser to ${HEALTH_URL}/health-health/# to see the frontend.
Conclusions
Even if the project only started towards the end of 2018, it is already possible to run a full CD pipeline for a relatively complex helm chart. It took me only a few small PRs to get everything working fine. There are several limitations to be aware of, however, the team is well aware of them and working quickly towards their resolution. Some examples:
- Tasks can only be executed sequentially
- Images as output resources are not really implemented yet
- Triggers are only manual
There’s plenty of space for contributions, in the form of bugs, documentation, code or even simply sharing your experience with knative pipelines with the community. A good place to start are the GitHub issues marked as help wanted. All the code I wrote for this is available on GitHub under Apache 2.0, feel free to re-use any of it, feedback and PRs are welcome.
Caveats
The build-pipeline project is rather new, at the moment of writing the community is working towards its first release. Part of the API may still be subject to backward incompatible changes and examples in this blog post may stop working eventually. See the API compatibility policy for more details.
Build pipelines have been renamed as Tekton pipelines now, and consequently all the
apiVersions are now*.tekton.dev.